
The Non-Negotiable “Big Two”: Every technical SEO strategy must employ Google’s Rich Results Test to verify strict SERP feature eligibility, alongside the official Schema.org Validator to ensure universal syntax perfection for non-Google AI engines like Claude and ChatGPT.
Ongoing Monitoring vs. Spot Checking: Validating code on launch day is insufficient due to constant CMS updates and plugin conflicts. Google Search Console’s Enhancements Tab serves as the ultimate automated intelligence tool for monitoring domain-wide schema health at scale.
The Enterprise Crawlers: For large-scale domains and e-commerce sites, checking URLs individually is impossible. Advanced technical crawlers like Screaming Frog and Sitebulb are essential to extract, validate, and audit entity relationships across the entire website simultaneously.
A Watershed Moment for Visibility
The landscape of search engine optimization and digital visibility has undergone a profound metamorphosis by the year 2026. For over two decades, the primary objective of search marketing was singularly focused on a relatively straightforward goal: secure a top position among ten blue links on a Search Engine Results Page (SERP) through keyword density, content silos, and rudimentary backlink acquisition. However, the exponential proliferation of large language models (LLMs), agentic workflows, and conversational search interfaces has fundamentally fractured this traditional model, pulling the industry into a new era of digital discovery.
The industry is currently experiencing the realization of stark analytical predictions indicating that traditional search engine volume is undergoing a precipitous 25% drop, with search marketing rapidly losing market share to AI chatbots and virtual agents. Google, while still processing an estimated 14 billion search queries daily, is facing unprecedented pressure from AI-powered search systems and conversational interfaces. ChatGPT alone has surged to over 700 million weekly active users, securing its position as the fourth most visited website globally with over 5 billion monthly visits. As artificial intelligence models reach billions of users globally, the fundamental behavior of the digital consumer has shifted permanently. Users no longer seek a list of resources to manually sift through; they demand immediate, synthesized answers delivered directly on the results page or within a chat interface.
For Small and Medium-sized Enterprises (SMEs), this algorithmic paradigm shift represents both a formidable operational challenge and an unprecedented commercial opportunity. The modern search environment mandates that optimization can no longer be treated as an isolated, one-time technical exercise relegated to the IT department. With the rise of zero-click searches, traditional strategies are falling critically short. Studies reveal that higher-ranking websites are now getting significantly fewer clicks than before; even top-ranking results experience click-through rate (CTR) drops of up to 30% due to the immediate satisfaction provided by AI overviews.
These shifting consumer behaviors and algorithmic updates have elevated two new critical disciplines: Generative Engine Optimisation (GEO) and Answered Engine Optimisation (AEO).
Generative Engine Optimisation and Answered Engine Optimisation
Generative Engine Optimisation is widely expected to surpass traditional optimization methodologies by 2026. It is defined as the strategic practice of structuring and writing content to rank highly and accurately within AI-generated responses. Unlike traditional methodologies that aimed merely to crack the algorithm for ranking positions, GEO focuses on becoming the foundational truth that AI systems draw upon when formulating comprehensive answers. Michael King, Founder and CEO of the digital marketing agency iPullRank, notes that the industry is shifting toward a framework called ‘relevance engineering,’ which fuses AI, information retrieval, content strategy, user experience (UX), and digital PR.
A highly specialized subset of this broader framework is Answered Engine Optimisation (AEO). While broad generative strategies target deep research queries, AEO targets the immediate inquiry—the “who, what, when, where, and why” of an industry. AEO is the structural strategy that focuses almost exclusively on formatting content to appear seamlessly in featured snippets, AI Overviews, localized answer boxes, and conversational voice assistant outputs. It deliberately shifts focus away from driving clicks to a website, prioritizing instead the inclusion of the brand’s data directly on the results page—often referred to as securing “Position Zero”.
The Foundational Role of Schema Markup in the AI Era
To achieve visibility in these zero-click environments and establish immediate trust with the searcher, the technical foundation of a website must be meticulously engineered to communicate directly with machine learning parsers. This communication is not facilitated by standard HTML text paragraphs; it is facilitated through advanced structured data, specifically Schema markup.
In 2026, Technical SEO mandates the implementation of rigorous, flawless schema markup. While traditional search engines historically utilized schema merely to generate visual “rich snippets” (such as star ratings or recipe cooking times), AI answer engines utilize structured data as a direct, explicit extraction map. Content that is organized with crystal-clear information hierarchies—utilizing logical heading structures, linear topic progression, and explicit semantic relationships defined by JSON-LD code—gets cited exponentially more frequently. Generative machines can parse and synthesize this explicitly defined data without algorithmic friction, drastically reducing the computational cost of information retrieval.
The digital landscape requires the implementation of several high-priority structured data formats to feed Retrieval-Augmented Generation (RAG) pipelines. As LLMs parse vast quantities of text, they search for definitive, factual answers using Paragraph Schema, Text-Block Markup, Video Schema with transcript integration, FAQ Schema, and Product or Offer markup. By grasping how schema markup explicitly defines content for artificial intelligence, business owners can ensure upcoming campaigns align with the latest Search Generative Experience trends.
However, executing this strategy requires absolute precision. AI parsers are highly intolerant of malformed code. A single missing property, an incorrect nesting hierarchy, or an outdated vocabulary string can render an entire page’s schema invisible to an LLM. Therefore, comprehensive testing and validation are no longer optional best practices—they are the critical failure points of modern digital marketing. To navigate this demanding technical landscape, professionals must deploy a sophisticated testing stack. The following analysis explores the five essential testing tools required to validate schema markup and secure dominance in 2026.
1. Google’s Rich Results Test: The Non-Negotiable Baseline
The first essential tool in any modern technical workflow is Google’s Rich Results Test. This platform serves as the definitive, foundational arbiter of whether a specific web page is eligible for Google’s proprietary rich results and, by extension, inclusion within Google’s specific AI Overviews. While the ecosystem has expanded beyond a single search engine, Google AI Overviews still reach the broadest audience by virtue of the platform’s dominant search market share, integrating directly into existing search behavior. Therefore, satisfying Google’s specific parser remains the absolute baseline.
Validating SERP Eligibility and Strict Feature Requirements
The Rich Results Test is not designed to be a generic syntax checker; it is a highly specialized tool designed to verify whether implemented markup meets Google’s notoriously strict feature requirements. Google supports a distinct, limited subset of the broader Schema.org vocabulary. Each supported feature—whether it is an Article, LocalBusiness, Product, FAQPage, or DiscussionForumPosting—requires specific mandatory properties to trigger visual SERP enhancements or AI summary eligibility.
When code is submitted to the Rich Results Test—either via a direct code snippet paste or by fetching a live URL—the tool renders the page and evaluates the structured data directly against Google’s current indexing engine ruleset. If a business owner is attempting to implement Product schema but fails to include the required price or priceCurrency properties within the Offer nested item, the Rich Results Test will immediately flag these omissions as critical errors. A critical error renders the page entirely ineligible for product carousels or merchant listings.
Furthermore, the tool evaluates the presence of recommended properties. Including only required properties while omitting recommended properties reduces the overall effectiveness and context of the schema. The Rich Results Test highlights warnings for missing recommended fields like author, dateModified, or image, providing developers with a roadmap to increase the semantic richness of their content.
The Importance of Crawl Rendering and JavaScript Execution
One of the most critical functions of the Rich Results Test in 2026 is its capability as a rendering diagnostic tool. Modern web development heavily relies on client-side rendering frameworks such as React, Angular, or Vue.js. In many enterprise architectures, structured data is not hard-coded into the static HTML; rather, it is dynamically injected into the Document Object Model (DOM) via JavaScript after the initial page load.
Because the Rich Results Test executes JavaScript in real-time, it allows technical teams to verify whether Googlebot can actually perceive the injected data during its crawl. Google has strict timeouts for JavaScript execution. If the schema fails to load within this rendering window, the Rich Results Test will report no detected items, alerting the development team that despite the code existing in the application logic, it acts as an invisible barrier to the search engine. This rendering verification is crucial; if Google cannot render the schema, the page cannot be indexed for rich results, effectively erasing the brand from zero-click SERP features.
Adaptation to Deprecations and Emerging Search Features
Google frequently updates its supported structured data guidelines, adding new features and deprecating outdated ones. The Rich Results Test reflects these changes in real-time, serving as an educational compliance tool.
For example, tracking the evolution of Google’s schema support reveals rapid shifts in focus. By early 2026, Google added new supported properties for Discussion Forum and QA Page markup, reflecting the AI engine’s hunger for user-generated consensus and conversational data. Conversely, the platform frequently deprecates features that no longer align with user intent or AI integration. The Practice problem schema, which previously populated specific educational rich results, was deprecated and marked for removal from Search Console reporting by January 2026. Documentation for course info, estimated salary, and vehicle listing was also systematically removed as those specific visual enhancements were phased out.
By continuously running deployment candidates through the Rich Results Test, an SEO Consultation team ensures that their code adheres to the most current iteration of Google’s algorithm, avoiding the deployment of deprecated markup that provides zero algorithmic benefit.
2. The Official Schema.org Validator: Ensuring Universal Vocabulary Compliance
While Google’s Rich Results Test is mandatory, relying on it exclusively is a critical strategic error in 2026. The search landscape is now highly fragmented, with millions of users bypassing traditional search engines entirely in favor of standalone AI platforms. Tools like OpenAI’s ChatGPT, Anthropic’s Claude, and Google’s own Gemini model represent diverse alternatives with distinct data ingestion behaviors. Analysis shows that these LLMs actively cite a wide variety of sources; for instance, ChatGPT cites Wikipedia for nearly 47.9% of factual queries, followed heavily by educational resources and heavily structured news sites.
These independent AI systems do not rely solely on Google’s proprietary guidelines; they rely on the foundational, universal standards established by the Schema.org community. Consequently, the official Schema.org Validator forms the essential second half of the non-negotiable “Big Two” spot-checking tools. Every technical professional must use Google’s Rich Results Test to confirm Google SERP eligibility alongside the official Schema.org Validator to catch syntax errors and ensure vocabulary correctness for all non-Google search engines.
Validating the Entire Semantic Ontology
The primary advantage of the Schema.org Validator is that it checks raw syntax and semantic structure against the entire Schema.org vocabulary—both the main release and pending extensions. Google only cares about the approximately 35 schema types that trigger its specific visual enhancements. The Schema.org Validator, however, evaluates all hundreds of available types.
This distinction is the cornerstone of advanced Generative Engine Optimisation. An organization might implement highly specific, descriptive structured data, such as MedicalCondition, RealEstateListing, GovernmentService, or FinancialProduct. Google’s Rich Results Test might simply ignore this markup, reporting no actionable items, because it does not have a stylized SERP box designed for a MedicalCondition. However, an independent AI answer engine tasked with formulating a complex response about medical symptoms or local financial regulations will highly value this explicit semantic categorization. The Schema.org Validator ensures that this critical, non-Google data is structurally sound, syntactically flawless, and ready for ingestion by any machine learning crawler.
Catching Incorrect Nesting and Deprecated Vocabularies
Analysis of common schema deployment failures across SMEs reveals that syntax anomalies, particularly incorrect nesting, are the primary culprits behind AI indexing failures. Schema types possess highly specific property requirements and hierarchical nesting rules. The Schema.org Validator meticulously maps the implemented code against the complete ontological structure to prevent these errors.
For example, if a developer attempts to declare a publisher within an Article schema, the publisher property specifically expects an Organization or Person object to be nested within it. If the developer mistakenly inputs a simple text string (e.g., "publisher": "Woonyb") instead of a nested entity object, the Schema.org Validator will flag this as a critical type mismatch. While an LLM is sophisticated at reading text, providing malformed data structures forces the algorithm to guess the context, introducing algorithmic friction that lowers the content’s confidence score and citation likelihood.
Furthermore, the Validator identifies the use of deeply outdated frameworks. If a legacy website utilizes an old data-vocabulary.org structure instead of modern schema.org conventions, the Validator will immediately flag the deprecation. Resolving these syntax and hierarchical errors ensures that the data layer acts as a unified, unambiguous source of truth for every crawler on the internet, perfectly aligning with the core requirements of Answered Engine Optimisation.
3. Google Search Console (The Enhancements Tab): Ongoing Monitoring at Scale
Validating code perfectly during a website launch or when publishing a new blog post is a necessary first step, but it is entirely insufficient for sustainable organic growth. Websites are living, breathing ecosystems. Content management systems update, third-party SEO plugins conflict with theme files, and non-technical staff frequently alter page structures, inadvertently breaking complex JSON-LD implementations. Validating code during launch isn’t enough; ongoing monitoring is required.
Google Search Console (GSC), and specifically its Enhancements Tab, serves as the ultimate diagnostic tool for monitoring schema health at scale and catching critical errors as they happen over time.
The Evolution of GSC in the AI-First Environment
By 2026, Google Search Console has evolved far beyond its origins as a basic diagnostic dashboard; it has become a sophisticated search intelligence platform that exposes exactly how Google’s AI interprets and categorizes site content. With AI-powered search experiences becoming mainstream, mastering GSC is no longer optional for digital marketers—it is the central command station for visibility.
The Enhancements Tab aggregates all detected structured data across an entire verified domain, automatically categorizing the data into distinct search features such as FAQ, Product Snippets, Merchant Listings, Videos, and Sitelinks search boxes. This provides a macro-level view of the website’s technical health.
Catching Critical Errors Over Time
When a core WordPress update or an e-commerce platform migration inadvertently strips the aggregateRating or shippingDetails properties from thousands of product pages, checking those URLs one by one via the Rich Results Test is functionally impossible. Search Console automates this domain-wide surveillance.
If a critical error arises—such as a missing required field that disqualifies a previously healthy page from rich results and AI Overviews—GSC immediately flags the affected URLs, categorizes the issue under the “Invalid” status, and dispatches automated email alerts to the verified administrative team. This real-time agility is crucial. Maintaining a fast response to technical anomalies ensures that immediate structural issues are resolved before a brand is delisted from an AI citation pool.
Furthermore, GSC meticulously categorizes issues into “Errors” (which prevent enhancements entirely) and “Warnings” (which highlight missing recommended properties). Addressing warnings over time is a core tactic in continuous Generative Engine Optimisation. As AI engines demand deeper context to fuel their answers, populating optional attributes elevates the content’s perceived comprehensiveness, thereby increasing its likelihood of being selected as a primary source.
AI-Powered Configuration and Indexing Intelligence
To assist professionals in parsing massive datasets, the 2026 iterations of Google Search Console introduced experimental AI-powered configurations designed to streamline performance analysis. This feature allows an SEO specialist to utilize natural language queries to instantly filter and compare complex data without manual setup. For instance, a user can instruct GSC to “Compare traffic for my pages that contain ‘/blog’ in this quarter to the same quarter last year,” or “Show me the Average CTR and Average Position of my queries in Spain in the last 28 days”. This allows teams to directly correlate the resolution of schema errors in the Enhancements tab with actual lifts in organic AI visibility.
Equally important to the Enhancements tab is the GSC Indexing report, which reveals whether machine-readable content is actually being ingested. Crawl efficiency directly impacts AI indexing.

By actively utilizing Google Search Console, technical teams transform reactive debugging into proactive monitoring, ensuring that the critical communication pipeline between their website and global AI models remains unobstructed.
4. Screaming Frog SEO Spider: The Enterprise Crawling Standard
While Google Search Console is excellent for monitoring URLs that Google has already crawled and decided to report on, it possesses a distinct blind spot: it relies on Google’s timeline and algorithms. For sites with thousands of pages, deep information architectures, and complex dynamic templates, relying solely on reactive data is insufficient. Proactive, immediate, domain-wide auditing is required.
This necessitates the use of technical enterprise crawlers. Mentioning technical SEO crawlers like Screaming Frog is absolutely essential, as these tools can extract and validate structured data across an entire domain in one single crawl, which is how top-tier professionals actually audit schema.
Domain-Wide Extraction and API Validation
Screaming Frog integrates a proprietary structured data validator directly into its crawling architecture, bypassing the need to use manual spot-checking tools for large-scale audits. When an analyst configures the software for a 2026 schema audit, they navigate to the extraction configuration and actively enable JSON-LD, Microdata, and RDFa extraction formats. Crucially, the software allows the user to run concurrent checks by enabling both “Schema.org Validation” and “Google Rich Result Feature Validation” simultaneously.
As the SEO Spider crawls the target website—navigating from the homepage through every category, subcategory, and individual post—it parses every single URL, extracts the embedded structured data, and cross-references it against real-time API rulesets. The software generates a dedicated “Structured Data” tab containing advanced filtering mechanisms. Analysts can instantly isolate URLs containing validation errors, view the exact property values causing the friction, and examine the precise validation message dictating the required fix.
Custom Extraction for Answer Extraction Readiness
In the context of 2026 AI search optimizations, Screaming Frog’s capabilities extend far beyond basic schema compliance. It serves as a primary diagnostic layer to ensure that answer engines can reliably retrieve, understand, and cite content. A standard technical crawl is effectively turned into an “answer extraction readiness” audit through the use of Custom Extraction.
Analysts use RegEx, XPath, or CSS Path extraction rules to identify definition blocks, FAQ patterns, author/about signals, and key entity mentions across thousands of URLs. By cross-referencing these extracted textual elements with the presence of validated schema (such as FAQPage or ProfilePage), auditors can guarantee that the content is explicitly machine-readable.
Furthermore, 2026 builds of Screaming Frog include AI integrations that assist in generating alt text or running custom AI classification prompts directly on the crawled data. While this AI-assisted extraction acts as a powerful helper for classification and triage, professionals treat it like QA, manually reviewing coverage and consistency before shipping mass changes.
Crawl Depth, Rendering, and Orphan Diagnostics
A critical operational KPI for AI visibility is ensuring that structured data resides at an optimal crawl depth and is properly connected to the site’s semantic graph. AI indexing requires clear relationships between entities.
Screaming Frog’s advanced configuration addresses these architectural prerequisites:
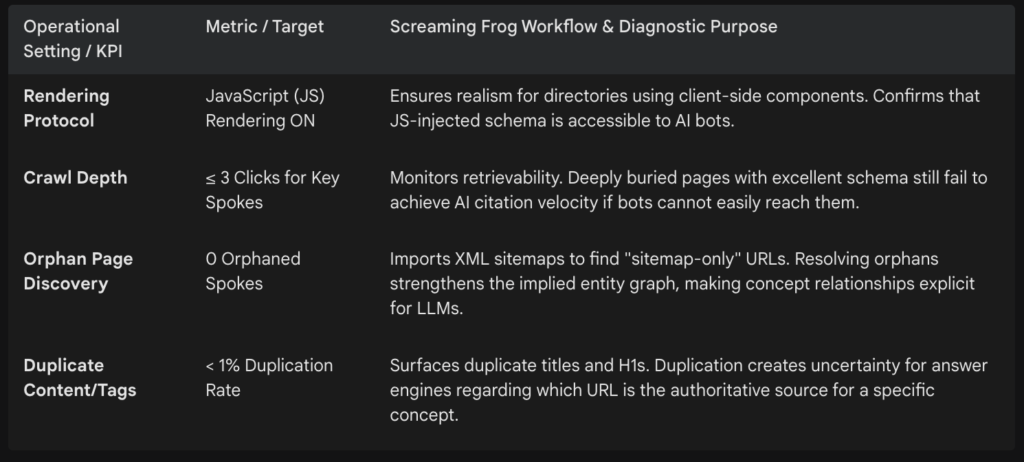
By deploying Screaming Frog, technical teams eliminate the highest-leverage friction points—reducing crawl depth, repairing canonical conflicts, eliminating orphan pages, and standardizing structured data across entire server infrastructures. This comprehensive approach guarantees that when an AI bot arrives, it encounters a perfectly mapped, highly efficient data architecture.
5. Sitebulb: Entity-Centric Auditing and Executive Reporting
The fifth indispensable tool in the 2026 schema validation arsenal is Sitebulb. While Screaming Frog excels in raw data extraction and granular technical configurations, Sitebulb distinguishes itself through its intuitive visualizations, entity-based auditing capabilities, and sophisticated structured data discovery reporting. It is specifically engineered to bridge the communication gap between technical SEO execution and executive-level strategic planning, making it a critical tool for providing comprehensive Marketing consultation.
Strict Validation and Intuitive Visualizations
Sitebulb’s structured data testing tool is engineered to strictly adhere to published documentation from both Schema.org and Google. Historically, various testing tools have suffered from internal contradictions or allowed malformed code to pass if a search engine temporarily tolerated it. Sitebulb enforces a rigid compliance standard. If a specific field is deemed “required” by official search guidelines, Sitebulb will definitively flag its absence as an error, even if the page is currently enjoying rich results in the SERPs. This strict adherence future-proofs the website against sudden core algorithm updates and increasingly strict AI parsing models.
The first time a technical auditor crawls a new client’s website, they often do not know what structured data architectures they are going to encounter. Sitebulb automatically categorizes what structured data is present and aggregates issues so that strategists can understand failures at a macro “template level” before drilling down into micro “page-level” anomalies. Its intuitive visualizations help teams quickly understand the site’s semantic profile, making the data ideal for dropping into client presentations and executive strategy meetings.
The E-commerce Entity Mismatch Challenge
In the 2026 digital retail environment, AI systems increasingly reason over “product entities” rather than individual URLs. An entity is the complete set of signals, attributes, pricing data, and reviews defining a product across the entire web. This marks a massive shift from page-centric optimization to entity-centric strategy.
A highly prevalent and detrimental issue in modern e-commerce is the inconsistency between on-page JSON-LD schema, centralized Product Information Management (PIM) systems, and external data feeds like the Google Merchant Center (GMC). If a product page schema declares a price of $89.99, but the GMC feed lists $94.99, this mismatch immediately signals unreliability to AI systems. Inconsistencies across thousands of SKUs drastically reduce a product’s probability of inclusion in commercial AI Overviews or personalized agentic recommendations.
Sitebulb’s deep auditing functionality surfaces these errors and inconsistencies across massive e-commerce crawls, highlighting mismatches between declared schema types and missing entity attributes. By resolving these domain-wide discrepancies, SEOs, Paid Media teams, and Merchandising departments can collaborate to ensure that all data layers present a unified, deterministic truth to machine learning models.
Rendered vs. Non-Rendered Comparisons
Similar to Screaming Frog, Sitebulb addresses the reality that crawlability is “step zero” in the AI era. AI tools like ChatGPT utilize real-time web fetching to retrieve the absolute freshest data—such as dynamic pricing, current stock status, and the latest user reviews—because LLMs specifically seek out real-time information that their static training data lacks.
If this critical information is injected via JavaScript that fails to execute properly, it remains entirely invisible to AI bots. Sitebulb allows users to turn on JavaScript crawling and directly compare the DOM states—what is visible with execution versus what is visible without execution. This allows technical teams to definitively prove whether key product information and structured data are inaccessible to basic crawlers, prompting necessary architectural shifts to server-side rendering or dynamic rendering solutions.
Emerging AI Visibility Tracking in 2026
While the five essential tools detailed above form the absolute core of technical schema validation, mastering the Search Generative Experience requires understanding how validated schema directly influences downstream visibility. Once the structured data is proven to be technically flawless via Screaming Frog and Sitebulb, and continuously monitored via GSC, organizations must measure the outcome of that data.
This necessity has given rise to a secondary layer of tools focused on AI mention tracking and generative visibility reporting. As organic click-through rates for traditional top results decline significantly, measuring AI citations, monitoring assisted conversions, and tracking placements inside AI answers have become the primary Key Performance Indicators (KPIs) for AEO strategies.
Tracking Citation Velocity and AI Mentions
Emerging platforms such as Semrush Enterprise AIO, Ahrefs Brand Radar, SE Ranking, and specialized trackers like Peec AI and Otterly are utilized to scale the tracking process. These tools do not validate the raw code; they scrape and monitor the AI interfaces to report on how often a brand’s entities are mentioned and who shows up in synthesized answers.
Research data from 2026 indicates that new, perfectly structured content enters AI citation pools within 3 to 5 business days. However, content also decays rapidly; pages that are not updated within a 14-day window show a 23% decline in AI citation frequency. By monitoring “citation velocity”—tracking how often AI cites your content monthly and updating outdated citations—brands can treat Answered Engine Optimisation as an ongoing, empirical test-and-learn process.

If an organization maintains flawless schema (validated by the Big Two) and a perfect internal architecture (verified by the Enterprise Crawlers) but still suffers from low AI visibility, it indicates a deficiency in broader E-E-A-T (Experience, Expertise, Authoritativeness, and Trustworthiness) signals.
The Convergence of Schema and E-E-A-T
It is crucial to recognize that technically valid schema is a prerequisite, not a panacea. The principles of E-E-A-T remain the foundational framework for Google’s algorithms and extend natively to AI tools like Gemini and Search Generative Experience. Structured data simply makes these subjective human signals machine-readable.
For example, simply writing an author biography is insufficient. By explicitly marking up that biography with Person schema, linking to external verified credentials, academic publications, or verified social profiles via the sameAs property, and utilizing Organization markup to establish the publisher’s corporate legitimacy, a brand translates its real-world authority into a semantic format that generative algorithms can definitively parse, verify, and trust. The website itself transitions from being merely a conversion mechanism to serving as a vital “trust signal”; as AI handles the research phase, users and agents visit the site primarily to verify credibility.
Strategic Implementation and Cross-Departmental Agility
The restructuring of the digital search ecosystem in 2026 mandates that these technical implementations are accompanied by high-level strategic alignment. Establishing precise objectives ensures that strategies focus on qualified lead generation rather than superficial traffic metrics that are easily eroded by zero-click SERPs.
For SMEs operating in highly competitive markets, executing this level of sophisticated entity building often requires cross-departmental collaboration between SEO, Paid Media, and Merchandising teams. Translating technical concepts like “entity building” into actionable business strategies requires immense expertise. Partnering with an experienced SEO Consultant Selangor or engaging in dedicated marketing consultation is frequently necessary to navigate these complexities.
A premier strategic approach involves monthly reporting and consultation, ensuring real-time agility to resolve technical anomalies before AI crawlers delist a brand. It involves continuous keyword research targeting the “who, what, when, where, and why” micro-queries that feed AEO , and executing the complex JSON-LD schema stacking (e.g., Article + ItemList + FAQ) required to dominate listicle-format ranking pages.
Engineering Relevance for the Future
The transition toward generative AI discovery has forever altered the mechanics of digital visibility, tearing down the traditional methodologies of the past two decades. To thrive in 2026, small and medium-sized enterprises must pivot away from outdated optimization tactics that chase blue links, and fully embrace the rigorous structural requirements of Generative Engine Optimisation and Answered Engine Optimisation.
The absolute foundation of this new visibility paradigm rests on the deployment of flawless, comprehensive structured data. Schema markup is the language of artificial intelligence. By utilizing Google’s Rich Results Test and the official Schema.org Validator for precise, strict spot-checking; employing Google Search Console for automated, ongoing health monitoring at scale; and unleashing the unparalleled power of enterprise technical crawlers like Screaming Frog and Sitebulb for deep architectural and entity-centric auditing, technical teams can ensure their digital assets act as the definitive, deterministic source of truth for global AI models.
Mastering these five essential testing tools ensures that your brand’s voice, personality, and expertise are accurately synthesized and presented to the modern digital consumer, right at the moment of their immediate inquiry.
If you are looking forward for someone to bring your SEO to another level, we are here to help. Discover how strategic SEO Marketing and AI-driven methodologies can transform your digital footprint and secure your market dominance in the era of artificial intelligence.



